Sunday, September 20, 2015
Blog Statistics with StatCounter & R
If you're interested in analysing your blog's statistics this can easily be done with a web-service like StatCounter (free, only registration needed, quite extensive service) and with R.
After implementing the StatCounter script in the html code of a webpage or blog one can download and inspect log-files with R with some short lines of code (like below) and then inspect visitor activity..
Read more »
After implementing the StatCounter script in the html code of a webpage or blog one can download and inspect log-files with R with some short lines of code (like below) and then inspect visitor activity..
url <- "http://statcounter.com/p7447608/csv/download_log_file?form_user=MYUSERNAME&form_pass=MYPASSWORD"
file <- paste(tempdir(), "\\log", ".CSV", sep = "")
download.file(url, dest = file)
log <- read.csv(file, as.is = T, header = T)
str(log)
'data.frame': 500 obs. of 19 variables:
$ Date.and.Time : chr "2011-12-19 23:32:30" "2011-12-19 23:20:04" "2011-12-19 23:16:24" "2011-12-19 23:14:40" ...
$ IP.Address : chr "93.129.245.130" "128.227.27.189" "207.63.124.250" "140.247.40.121" ...
$ IP.Address.Label: logi NA NA NA NA NA NA ...
$ Browser : chr "Chrome" "Firefox" "Chrome" "Firefox" ...
$ Version : chr "16.0" "8.0" "15.0" "6.0" ...
$ OS : chr "MacOSX" "WinXP" "Win7" "MacOSX" ...
$ Resolution : chr "1280x800" "1680x1050" "1280x1024" "1280x800" ...
$ Country : Factor w/ 44 levels "Argentina","Australia",..: 17 44 44 44 44 44 44 44 44 44 ...
$ Region : chr "Nordrhein-Westfalen" "Florida" "Illinois" "Massachusetts" ...
$ City : chr "Köln" "Gainesville" "Chicago" "Cambridge" ...
$ Postal.Code : int NA 32611 NA 2138 2138 NA 10003 2138 2138 2138 ...
$ ISP : chr "Telefonica Deutschland GmBH" "UNIVERSITY OF FLORIDA" "Illinois Century Network" "Harvard University" ...
$ Returning.Count : int 2 0 4 2 2 0 0 2 2 2 ...
$ Page.URL : chr "http://onlinetrickpdf.blogspot.com/2015/09/r-function-google-scholar-webscraper.html" "http://onlinetrickpdf.blogspot.com/2015/09/if-then-vba-script-usage-in-arcgis.html" "http://onlinetrickpdf.blogspot.com/2015/09/how-to-link-to-google-docs-for-download.html" "http://onlinetrickpdf.blogspot.com/2015/09/two-way-permanova-adonis-with-custom.html" ...
$ Page.Title : Factor w/ 53 levels "","onlinetrickpdf*",..: 36 50 23 46 10 20 13 9 10 46 ...
$ Came.From : chr "http://stackoverflow.com/questions/5005989/how-to-download-search-results-on-google-scholar-using-r" "http://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=3&ved=0CCwQFjAC&url=http%3A%2F%2Fonlinetrickpdf.blogspot.com%2F2011%"| __truncated__ "" "" ...
$ SE.Name : chr "" "" "" "" ...
$ SE.Host : chr "" "" "" "" ...
$ SE.Term : chr "" "" "" "" ...
Calculate Single Contour-Line from DEM with QGIS / GDAL
In QGIS:
- from menu: Raster / Extraction / Contour
- define output name path/to/output.shp
- alter GDAL call for single contour line at 900 m asl:
gdal_contour -fl 900 "path/to/dem_raster.asc" "path/to/output.shp"
- for removing small poplygons or lines add area or length field (attr table / field calc or vector / geometry / add geometry)
- query by length or area to deselect unwanted iso-lines
Finally, you can export the contours as KML and check it in Google Earth:

I downloaded my DEM-rasters (Nord-Tirol, Österreich) HERE
Read more »
- from menu: Raster / Extraction / Contour
- define output name path/to/output.shp
- alter GDAL call for single contour line at 900 m asl:
gdal_contour -fl 900 "path/to/dem_raster.asc" "path/to/output.shp"
- for removing small poplygons or lines add area or length field (attr table / field calc or vector / geometry / add geometry)
- query by length or area to deselect unwanted iso-lines
Finally, you can export the contours as KML and check it in Google Earth:

I downloaded my DEM-rasters (Nord-Tirol, Österreich) HERE
How to Download and Run Google Docs Script in the R Console

...There is not much to it:
upload a txt file with your script, share it for anyone with the link, then simply run something like the below code.
ps: When using the code for your own purpose mind to change "https" to "http" and to insert your individual document id.
pss: You could use download.file() in this way for downloading any file from Google Docs..
pss: You could use download.file() in this way for downloading any file from Google Docs..
# Example 1:
setwd(tempdir())
download.file("http://docs.google.com/uc?export=download&id=0B2wAunwURQNsMDViYzllMTMtNjllZS00ZTc4LTgzMzEtNDFjMWQ3MTUzYTRk",
destfile = "test_google_docs.txt", mode = "wb")
# the file contains: x <- sample(100); plot(x)
source(paste(tempdir(), "/test_google_docs.txt", sep = ""))
# remove files from tempdir:
unlink(dir())
# Example 2:
setwd(tempdir())
download.file("http://docs.google.com/uc?export=download&id=0B2wAunwURQNsY2MwMzNhNGMtYmU4Yi00N2FlLWEwYTctYWU3MDhjNTkzOTdi",
destfile = "google_docs_script.txt", mode = "wb")
# the downloaded script is the GScholarScraper-Function,
# read it and run an example:
source(paste(tempdir(), "/google_docs_script.txt", sep = ""))
# remove files from tempdir:
unlink(dir())
EDIT, MARCH 2013:
Method is outdated, use Tony's from below!
Convert OpenStreetMap Objects to KML with R
A quick geo-tip:
With the osmar and maptools package you can easily pull an OpenStreetMap object and convert it to KML, like below (thanks to adibender helping out on SO). I found the relation ID by googling for it (www.google.at/search?q=openstreetmap+relation+innsbruck).
Read more »
With the osmar and maptools package you can easily pull an OpenStreetMap object and convert it to KML, like below (thanks to adibender helping out on SO). I found the relation ID by googling for it (www.google.at/search?q=openstreetmap+relation+innsbruck).
# get OSM data
library(osmar)
library(maptools)
innsbruck <- get_osm(relation(113642), full = T)
sp_innsbruck <- as_sp(innsbruck, what = "lines")
# convert to KML
for( i in seq_along(sp_innsbruck) ) {
kmlLine(sp_innsbruck@lines[[i]], kmlfile = "innsbruck.kml",
lwd = 3, col = "blue", name = "Innsbruck")
}
shell.exec("innsbruck.kml")
Retrieve GBIF Species Occurrence Data with Function from dismo Package

library(dismo)
# get GBIF data with function:
myrger <- gbif("Myricaria", "germanica", geo = T)
# check:
str(myrger)
# plot occurrences:
library(maptools)
data(wrld_simpl)
plot(wrld_simpl, col = "light yellow", axes = T)
points(myrger$lon, myrger$lat, col = "red", cex = 0.5)
text(-140, -50, "MYRICARIA\nGERMANICA")
Taxonomy with R: Exploring the Taxize-Package
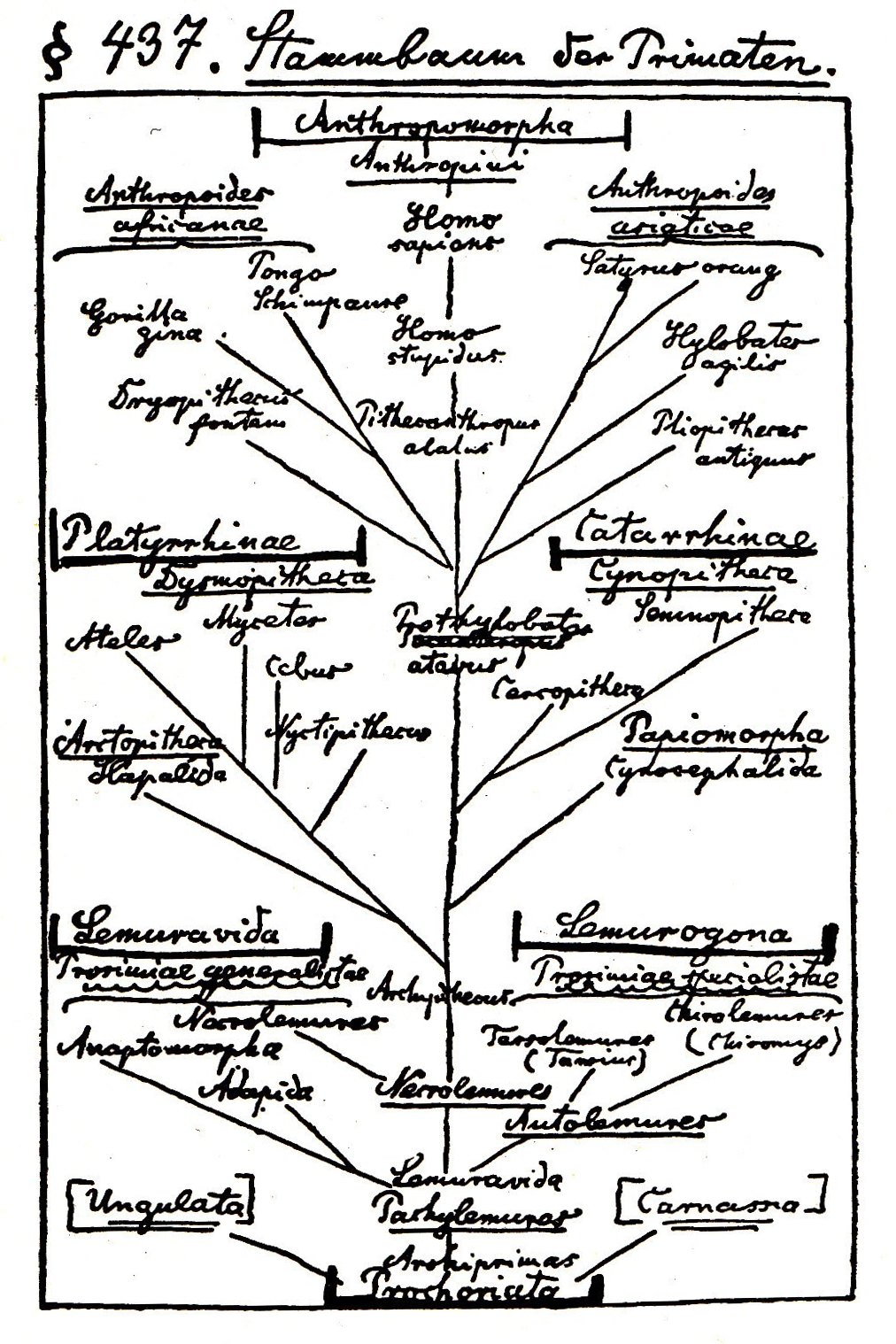 First off, I'd really like to give a shout-out to the brave people who have created and maintain this great package - the fame is yours!
First off, I'd really like to give a shout-out to the brave people who have created and maintain this great package - the fame is yours!So, while exploring the capabilities of the package some issues with the ITIS-Server arose and with large datasets things weren't working out quite well for me.
I then switched to the NCBI API and saw that the result is much better here (way quicker, on first glance also a higher coverage).
At the time there is no taxize-function that will pull taxonomic details from a classification returned by NCBI, that's why I plugged together a little wrapper - see here:
# some species data:
spec <- data.frame("Species" = I(c("Bryum schleicheri", "Bryum capillare", "Bryum argentum", "Escherichia coli", "Glis glis")))
spl <- strsplit(spec$Species, " ")
spec$Genus <- as.character(sapply(spl, "[[", 1))
# for pulling taxonomic details we'd best submit higher rank taxons
# in this case Genera. Then we'll submit Genus Bryum only once and
# save some computation time (might be an issue if you deal
# with large datasets..)
gen_uniq <- unique(spec$Genus)
# function for pulling classification details ("phylum" in this case)
get_sys_level <- function(x){ require(taxize)
a <- classification(get_uid(x))
y <- data.frame(a[[1]]) # if there are multiple results, take the first..
z <- tryCatch(as.character(y[which(y[,2] == "phylum"), 1]), # in case of any other errors put NA
error = function(e) NA)
z <- ifelse(length(z) != 0, z, NA) # if the taxonomic detail is not covered return NA
return(data.frame(Taxon = x, Syslevel = z))
}
# call function and rbind the returned values
result <- do.call(rbind, lapply(gen_uniq, get_sys_level))
print(result)
# Taxon Syslevel
# 1 Bryum Streptophyta
# 2 Escherichia Proteobacteria
# 3 Glis Chordata
# now merge back to the original data frame
spec_new <- merge(spec, result, by.x = "Genus", by.y = "Taxon")
print(spec_new)
# Genus Species Syslevel
# 1 Bryum Bryum schleicheri Streptophyta
# 2 Bryum Bryum capillare Streptophyta
# 3 Bryum Bryum argentum Streptophyta
# 4 Escherichia Escherichia coli Proteobacteria
# 5 Glis Glis glis Chordata
#
Download all Documents from Google Drive with R

# you'll need RGoogleDocs (with RCurl dependency..)
install.packages("RGoogleDocs", repos = "http://www.omegahat.org/R", type="source")
library(RGoogleDocs)
gpasswd = "mysecretpassword"
auth = getGoogleAuth("kay.cichini@gmail.com", gpasswd)
con = getGoogleDocsConnection(auth)
CAINFO = paste(system.file(package="RCurl"), "/CurlSSL/ca-bundle.crt", sep = "")
docs <- getDocs(con, cainfo = CAINFO)
# get file references
hrefs <- lapply(docs, function(x) return(x@access["href"]))
keys <- sub(".*/full/.*%3A(.*)", "\\1", hrefs)
types <- sub(".*/full/(.*)%3A.*", "\\1", hrefs)
# make urls (for url-scheme see: http://techathlon.com/download-shared-files-google-drive/)
# put format parameter for other output formats!
pdf_urls <- paste0("https://docs.google.com/uc?export=download&id=", keys)
doc_urls <- paste0("https://docs.google.com/document/d/", keys, "/export?format=", "txt")
# download documents with your browser
gdoc_ids <- grep("document", types)
lapply(gdoc_ids, function(x) shell.exec(doc_urls[x]))
pdf_ids <- grep("pdf", types, ignore.case = T)
lapply(pdf_ids, function(x) shell.exec(pdf_urls[x]))
Subscribe to:
Comments (Atom)